Поток Крупного Решения (Solution Train Flow): практики, метрики и ускорители потока
Что такое Поток Крупного Решения или Поток Поезда Решения?
Определение: Поток Крупного Решения или Поток Поезда Решения – это состояние, при котором Поезд Решения (Solution Train) обеспечивает непрерывную доставку клиенту ценных возможностей (Капабилити, Capabilities).
Дисциплина SAFe «Доставка и Интеграция Крупного Решения» (Large Solution Integration and Delivery) направляет взаимодействие Релизных Поездов (Agile Release Train, ART), помогая им работать согласованно, опираясь на общую миссию, и создавать крупные, критически важные системы. На практике применение этой дисциплины помогает организациям улучшать бизнес-результаты при разработке решений такого масштаба.
В то же время доставка решений на уровне предприятия всегда связана с высокой сложностью и зависимостью от взаимодействия между Релизными Поездами (ART), поставщиками, заказчиками и другими заинтересованными лицами. Любые задержки означают не только прямые потери времени и бюджета, но и упущенную возможность для тех, кто зависит от системы. Далее в статье рассмотрено, как выстроить непрерывный поток доставки ценности даже в условиях максимального масштаба и сложности.
О серии статей о потоке в SAFe
SAFe – фреймворк, основанный на потоке. Поэтому любые прерывания потока важно выявлять и устранять системно, чтобы обеспечивать непрерывную доставку ценности. Хотя рекомендации по управлению потоком встроены во многие элементы SAFe, отдельная серия из восьми материалов целенаправленно рассматривает типовые препятствия потоку:
- Управление Потоком Ценности
- Принцип #6 – Обеспечить непрерывный поток ценности
- Поток Команды
- Поток Поезда (ART)
- Поток Поезда Решения (Крупного Решения)
- Поток Портфеля
- Ускорение Потока с помощью SAFe
- Коучинг Потока
Восемь ускорителей потока: практики для уровня Поезда Решения (Крупного Решения)
SAFe выделяет восемь ускорителей потока, которые помогают диагностировать проблемы, оптимизировать работу и обеспечивать непрерывный поток на любом уровне фреймворка. В этой статье описано, как применять их на уровне Поезда Решения (Solution Train) при разработке крупных и сложных систем.
#1 Визуализируйте и ограничивайте незавершённую работу (НЗР, WIP)
Почему это важно?
Крупные системы неизбежно создают большой объём работ и задач. При этом, чтобы увеличить объём выполненного за фиксированное время, часто встречается управленческая реакция «добавить ещё работы». На практике избыточный объём незавершённой работы (НЗР, WIP) перегружает разработку, повышает риск выгорания, срыва сроков и перерасхода бюджета и в результате ухудшает экономические показатели.
Что делать?
- Сделайте всю незавершённую работу видимой.
На уровне Поезда Решения незавершённая работа обычно имеет два источника (рис. 1):
- Поток новых Капабилити (возможностей), «заходящих» в Канбан Систему Поезда Решения;
- Локальная дополнительная работа внутри Релизных Поездов (ART), необходимая для реализации видения в их части решения.
Управлять потоком невозможно, если учитывать только один источник незавершённой работы. Понимание и учёт обоих источников – основа для оценки общей загрузки системы и повышения пропускной способности.
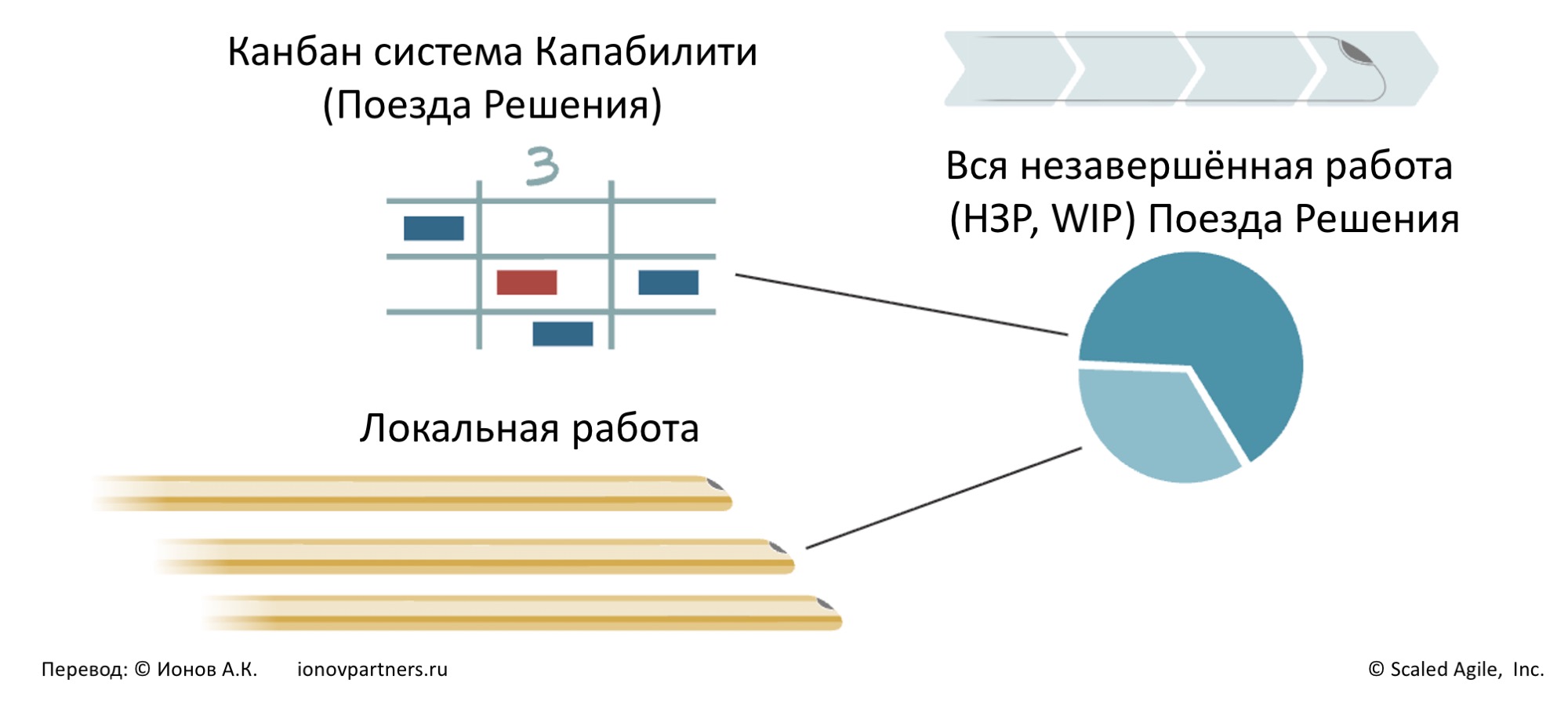
Рис. 1. Визуализируйте и снижайте WIP, распознавая два его основных источника.
- Сопоставляйте объём работ с доступной ёмкостью.
Лидерам Поезда Решения важно понимать ёмкость своих Релизных Поездов (ART) и поставщиков и регулярно корректировать Дорожную Карту Решения (Solution Roadmap), согласуя будущие Эпики и Капабилити с фактическими возможностями системы.
#2 Устраняйте узкие места
Почему это важно?
Доставка крупного решения опирается на множество ресурсов: людей, цепочки поставок, организационные структуры, существующие системы, инфраструктуру. Система работает настолько быстро, насколько позволяет самое узкое место. Поэтому узкие места нужно находить и устранять на постоянной основе.
Что делать?
- Находите узкие места через «наблюдаемость» процесса.
Используйте:
- визуализацию незавершённой работы по всем этапам конвейера доставки;
- фиксацию и анализ задержек и срывов вех (контрольных точек);
- обратную связь от команд разработки о проблемах в системе.
Мероприятия SAFe, включая «Инспект-Адапт» (Inspect & Adapt), поддерживают проактивное выявление и устранение узких мест.
- Устраняйте узкие места несколькими способами:
- Увеличивайте ёмкость в узком месте.Это очевидный первый шаг. Узкие места из‑за нехватки знаний или навыков устраняются за счёт привлечения дополнительных команд или «Общих Сервисов», подключения поставщиков, а также развивая «T‑shaped» компетенции в Поездах (ART) и командах, чтобы специалисты могли при необходимости переключаться на работу в узком месте. Узкие места, связанные с дефицитом ресурсов (например, тестовых сред) или недостаточной автоматизацией (ручные шаги сборки и интеграции) требуют целевых инвестиций.
- Перераспределяйте работу вокруг узкого места. Если «бутылочное горлышко» сохраняется, корректируйте Дорожную Карту Решения, фокусируясь на доставке ценности, которая не проходит через дефицитные ресурсы.
- Перераспределяйте работу между поставщиками. Убедитесь, что контракты и правила внутреннего управления позволяют передавать работу туда, где есть ёмкость. Проверьте, что правила управления обеспечивают разумный доступ к активам разработки (включая кодовые базы), а контракты не ограничивают изменение (пере)распределения работ (см. материал про Agile Контракты). Планируйте обучение заранее, чтобы больше команд могли подключаться к критически важным видам работ.
-
- Децентрализуйте принятие решений.
По мере ускорения команд и Поездов (ART) медленное принятие решений становится самостоятельным источником узких мест. Руководителям, не принявшим Lean-Agile Мышление, может быть сложно делегировать полномочия. Личное принятие и способствование принятию другими нового способа определения и оценки работы повышает качество, скорость и степень децентрализации решений.
#3 Минимизируйте передачи и зависимости
Почему это важно?
Крупные системы имеют множество связей, поэтому существенные зависимости между участниками разработки – нормальная ситуация. Однако излишние зависимости и передачи работы от одних к другим нарушают поток, создают ненужное переключение контекста и накладные расходы. Типичные последствия – задержки и перерасход бюджета.
Что делать?
Полностью устранить передачи и зависимости невозможно, но их можно заметно снизить:
- Разрабатывайте дизайн с учетом масштаба и модульности.
Архитектура крупного решения должна позволять Поездам (ART) и командам независимо, итеративно развивать дизайн и выпускать новую функциональность для получения обратной связи при минимальной внешней координации.
- Организуйтесь вокруг чётко определённого контекста.
Выстраивайте Поезда (ART) и команды вокруг ясных бизнес- и технических доменов, поддерживая относительно стабильные оргструктуры с минимально необходимым количеством зависимостей. Применяйте топологии Команд и Поездов (Team and ART Topologies), чтобы дополнительно снижать организационные зависимости.
- Создавайте действительно кросс-функциональные Поезда (ART) и команды.
Для сквозного потока ценности каждой команде и Поезду (ART) необходимы знания, ресурсы, навыки и полномочия, достаточные для принятия решений и доставки ценности с минимальными внешними зависимостями.
- Организуйте работу для поддержки инноваций.
Изменения чаще происходят в зонах высокой инновационности, поэтому на ранних этапах формируйте команды и Поезда (ART) вокруг этих зон. По мере прояснения дизайна применяйте архитектурные и организационные практики (включая топологии), чтобы снижать взаимозависимости.
- Внедряйте Lean-Agile практики во всей организации.
Подразделения закупок, ИТ, управление релизами (выпусками) и конфигурациями часто работают как независимые функциональные блоки. Это формирует «силосы», а процедуры приёмки могут не соответствовать новым способам доставки ценности. Обеспечьте единый Lean-Agile подход и при необходимости включайте эти функции в Поезда (ART).
#4 Обеспечивайте быструю обратную связь
Почему это важно?
Для крупных решений стоимость неудачи часто неприемлемо высока. Недостаток своевременной и корректной обратной связи приводит к масштабной переделке, непредвиденным задержкам, снижению удовлетворенности клиентов и потенциально недопустимым социальным и экономическим последствиям.
Ранняя обратная связь – отдельный вызов для разработчиков крупных решений. Клиенты могут находиться в других потоках создания ценности или быть конечными пользователями, существенно удалёнными от разработки.
Чтобы получать от них обратную связь быстро, команды должны заранее определить своих ключевых клиентов по всей сквозной цепочке доставки, кем бы эти клиенты не являлись: конечными пользователями, другими командами разработки, представителями производства или операционной деятельности и т. д. (рис. 2).
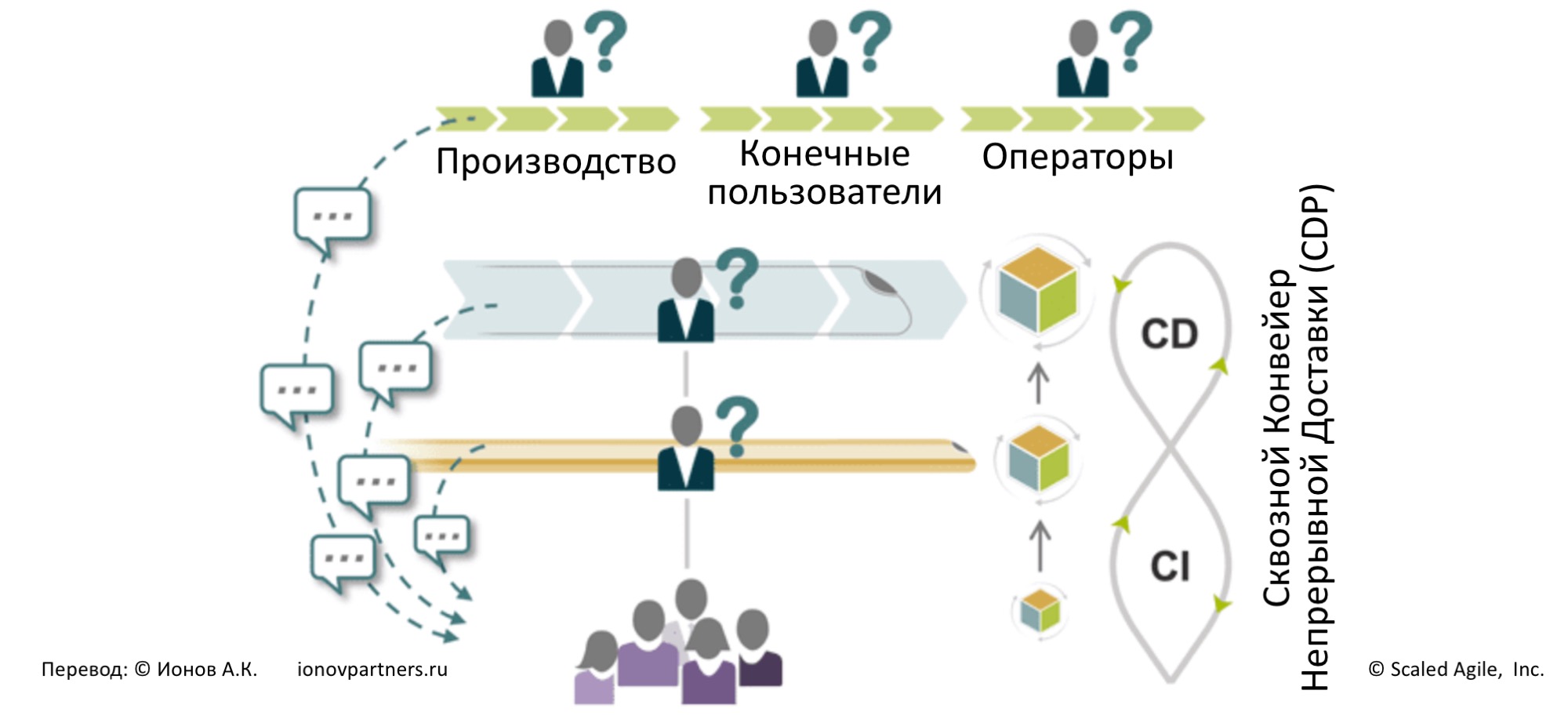
Рис. 2. Обеспечьте быструю обратную связь в рамках Поезда Решения.
Что делать?
- При необходимости находите «короткий путь» к клиенту.
На раннем этапе определите, кто лучше всего может предоставить обратную связь, и проактивно устраняйте организационные и иные барьеры взаимодействия с этими клиентами (рис. 3).
Используйте «персоны» (personas) и «карты пути клиентов» (journey maps), как основу клиентоцентричного подхода для понимания внешних и внутренних клиентов или заинтересованных лиц (с точки зрения клиентоцентричности это одно и то же).
Для клиентов, являющимися общими для нескольких команд и Поездов (ART), целесообразно формировать также и единый набор «personas» и «journey maps».
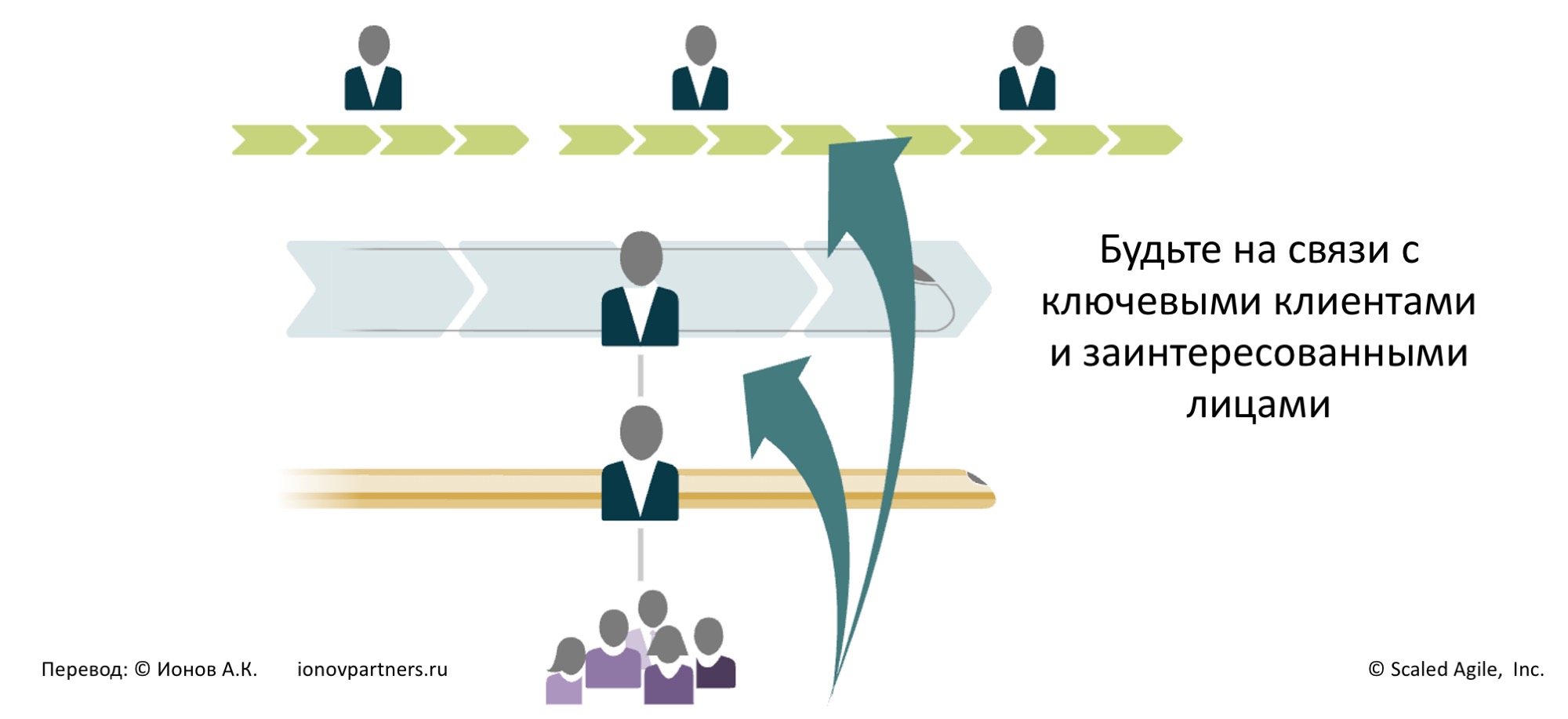
Рис. 3. Ищите короткие пути к внутренним и внешним клиентам.
- Обеспечьте ёмкость для обратной связи.
Быстрая обратная связь возможна только тогда, когда у заинтересованных лиц есть возможность её давать. Убедитесь, что нужные заинтересованные лица понимают важность своего вклада и выделяют время.
Со стороны разработки обеспечьте способность оперативно реагировать на обратную связь и корректировать решения.
- Интегрируйтесь часто.
Быстрая обратная связь требует способности быстро интегрировать небольшие изменения в большую систему. Поезда (ART) и команды постоянно работают над автоматизацией сквозного Конвейера Непрерывной Доставки (CDP), сокращающего время и усилия на доставку изменений для получения обратной связи (см. рис. 2).
Там, где сквозная интеграция непрактична, применяйте макеты и цифровые модели для получения ранней обратной связи.
- Встраивайте качество.
В больших системах небольшие дефекты компонентов или подсистем могут суммарно превращаться в крупные системные проблемы. Дополнительно усложняет ситуацию то, что дефекты трудно обнаруживать и диагностировать из‑за множества факторов, включая накопление того, что в другой ситуации выглядело бы как «незначительные сбои».
Поэтому важно, чтобы все участники признавали ценность использования «встроенного качества» и чтобы на каждом уровне были доступны адекватные тестовые среды в реалистичном контексте (окружении) Решения (рис. 4).
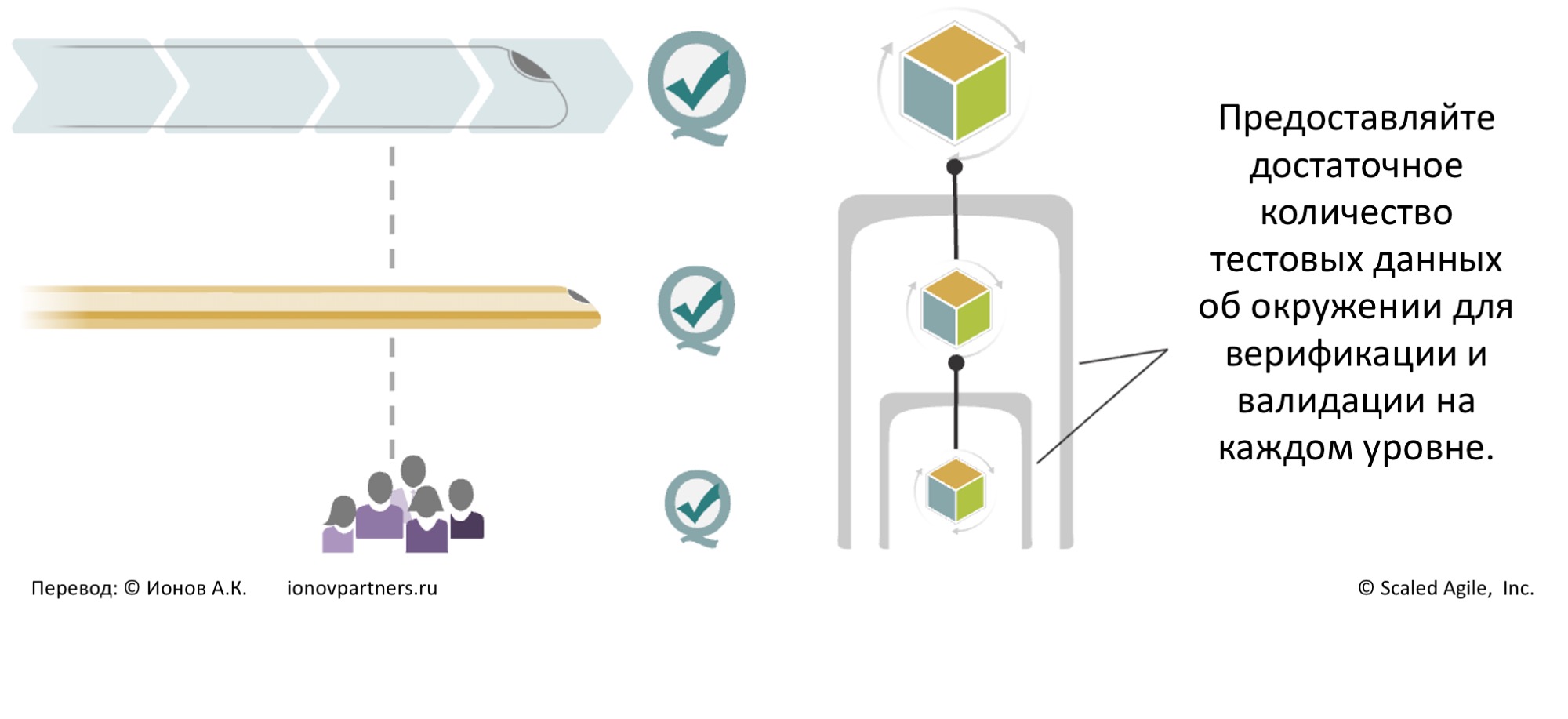
Рис. 4. Обеспечьте качество и достаточное тестирование в реалистичном контексте на каждом уровне.
#5 Работайте малыми партиями
Почему это важно?
Традиционный подход предполагает последовательность «формулирование требований – проектирование – разработка – тестирование – выпуск» крупными партиями. Это ограничивает поток и задерживает обратную связь, что приводит к дополнительным переделкам, поздним доставкам и снижению удовлетворённости клиентов.
Что делать?
- Уточняйте, создавайте дизайны и реализуйте решение небольшими «вертикальными срезами» ценности.
Работа малыми партиями требует от лидеров Поезда Решения инкрементального уточнения требований и дизайна.
Используйте временные рамки Интервала Планирования для определения объёма создаваемых новых возможностей (Капабилити) и исследовательских активностей.
- Фокусируйтесь на создании критически важного знания.
Чтобы уменьшать размеры партий, концентрируйте внимание команд и Поездов (ART) на том, что необходимо узнать с технической, рыночной или пользовательской точки зрения, и сужайте фокус только до работ, действительно необходимых для получения этого знания.
- Применяйте единую каденцию (единый ритм) на уровне всего Поезда Решения.
Общая каденция выступает практическим «принуждающим» фактором, уменьшающим размеры партий для всех участников. Каждый Интервал Планирования становится «событием вытягивания» («pull event»), собирающим небольшие изменения элементов решения в интегрированное целое для обзора и обратной связи.
- Оптимизируйте партию выпуска.
Вместо традиционной «одноразовой» разработки, Agile подход строит систему инкрементально и обеспечивает ранние и частые релизы ценности. Это усиливает необходимость оптимизации «партии выпуска».
Введите быстрый и надежный релизный процесс, который обеспечивает соответствие регуляторным требованиям (compliance), допускает ограниченные релизы для целевых сегментов клиентов и предусматривает стратегию отката, чтобы избежать прерывания сервиса при ошибках (см. Выпуск по Требованию).
#6 Сокращайте длину очередей
Почему это важно?
Традиционные подходы к уточнению требований, проектированию и реализации больших систем часто приводят к фиксированным многолетним графикам и длинным очередями незавершённой работы, за последовательность и список которых взяты жёсткие формальные обязательства.
Длинные очереди увеличивают время ожидания новой функциональности и снижают способность реагировать на изменения.
Хотя доля долгосрочного прогнозирования и фиксированные значимые контрольные точки, вероятно, сохранятся, очереди из «крупных еще не сделанных элементов» необходимо управляемо сокращать, чтобы улучшать время потока.
Что делать?
- Заменяйте фиксированные планы на дорожные карты (в формате «скользящего горизонта» или «накатывающейся волны», «rolling-wave»).
Где возможно, переход к дорожным картам «rolling-wave» повышает гибкость и адаптивность дизайна и доставки.
Дорожная карта Поезда Решения формирует высокоуровневый скользящий прогноз вех, дат и Эпиков, которые задают связанные Интервальные Дорожные карты ART и поставщиков на каждый из Интервалов Планирования.
Дорожные карты важно регулярно корректировать по мере появления новых технологий, пользователей и бизнес-фактов (рис. 5).
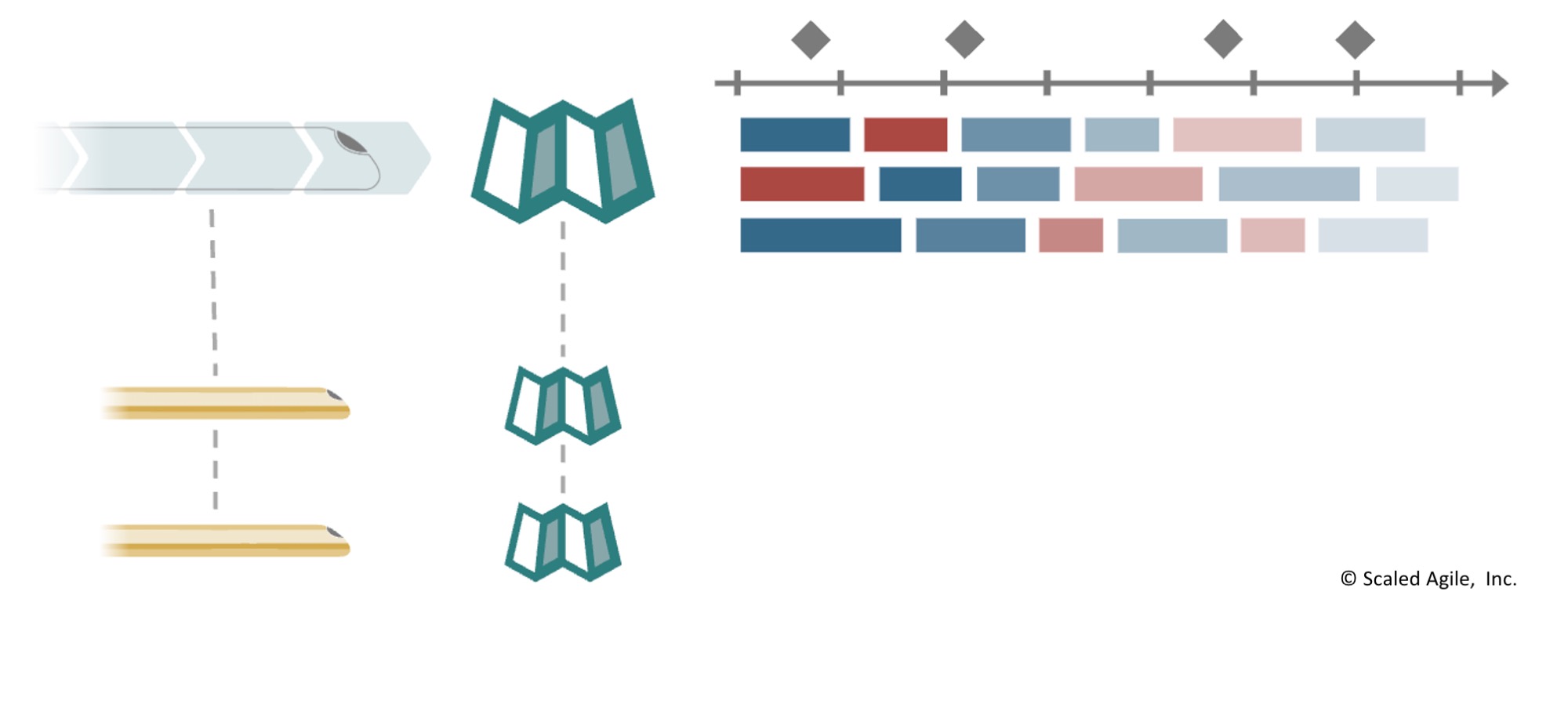
Рис. 5. Прогнозируйте и корректируйте работу с помощью связанных дорожных карт.
- Применяйте Множественный Дизайн (set-based design) для фиксированных вех.
Из‑за высокой стоимости изменений и необходимости координации (например, лётные испытания в авиации или значительный выпуск сложного программного продукта и т. п.) часть дат может быть фиксированной и неизменяемой.
В таких случаях Множественный Дизайн (Set-Based Design) помогает сохранить достаточную гибкость при достижении целей.
#7 Оптимизируйте время «в потоке»
Почему это важно?
Крупные системы характеризуются значительным объёмом работ, сложностью и требованиями надзора (governance). В результате Поезда (ART) и команды часто тратят непропорционально много времени на формальную маршрутизацию задач и связанные с этим конфликты, переключение контекста и отчётность – и недостаточно времени на создание решения.
Оптимизация времени «в потоке» позволяет специалистам сосредоточиться на создании решения без лишних прерываний.
Что делать?
- Выстраивайте эффективно работающий дизайн систем и всей организации.
В крупных системах команды могут регулярно блокироваться техническими или бизнес-вопросами вне их компетенций, назначения и миссии.
Создавайте дизайн системы и оргструктуру с корректным разделением ответственности, минимизируйте зависимости и сокращайте время встреч. Это освобождает время для фокусной работы над своей частью решения.
- Обеспечивайте эффективность мероприятий SAFe.
Контролируйте, чтобы PI Планирование и мероприятия по синхронизации на уровнях Релизных Поездов (ART) и Поезда Решения (Solution Train) были результативными.
Сокращайте или устраняйте лишние и дублирующие встречи, а также ручные активности по статус-отчетности.
#8 Устраняйте устаревшие практики и политики
Почему это важно?
Из‑за масштаба, затрат и ожидаемого эффекта разработка крупных решений заметна и мотивирует на повышенно детальное управление и надзор.
Многие надзорные активности – устаревшие практики, которые решали задачи в прошлом, но теперь создают новые препятствия потоку. Их необходимо выявлять и далее либо устранять, либо изменять, либо, хотя бы смягчать их противодействие.
На что обратить внимание
Типовые примеры создания неэффективности:
- традиционные модели управления проектами и программами (например, earned value management (EVM), work breakdown structure (WBS), проектно-ориентированный учёт затрат), наложенные поверх Agile разработки;
- функции качества и надзора (governance), навязывающие водопадные (stage-gate) контрольные точки, этапы, вехи;
- устаревшее управление поставщиками и контракты с фиксированными объёмом, сроками и поставляемыми артефактами;
- неверные стимулы, побуждающие людей оптимизировать создание «своей части» системы вместо оптимизации системы целиком;
- недостаток прозрачности у поставщиков и между ними, скрывающий критические факты до момента, когда уже поздно реагировать и стоимость реакции максимальна;
- «особое отношение» к источникам финансирования, политика или (воспринимаемые) юридические риски, которые препятствуют обучению и поддержке поставщиков там, где это нужно для потока;
- ограниченный доступ к конечным клиентам, необходимым для валидации решения;
- позднее подключение команд по верификации и валидации (V&V) и позднего контроля за соответствием регуляторным требованиям (комплаенсу).
Что делать?
Агенты изменений должны постоянно отслеживать и распознавать эти устаревшие правила и практики управления, которые мешают потоку.
Особенно важно работать с функциями регуляторного соответствия и регулирования (качество, сертификация, управление релизами): они могут воспринимать Lean-Agile трансформацию как риск для «проверенного» подхода. Помогите им получить знания и контекст, необходимые для успешной работы в среде SAFe, вовлекая их регулярно и на ранних этапах – до того, как контроль превратится в поздний барьер.
Измеряйте и улучшайте поток
Сложно улучшать то, что не измеряется. Поток – одна из трех областей измерений SAFe (см. Метрики SAFe) и помогает Поездам Решения выявлять проблемы и целенаправленно улучшаться.
Хотя все метрики потока SAFe применимы на уровне Поезда Решения, наиболее релевантны:
- время потока
- загрузка потока
- распределение потока
Ниже будет рассмотрено, как понимать каждую метрику на уроке Поезда Решения.
Время Потока (Flow Time)
Создание крупных систем порождает огромный объём параллельной активности: сотни и тысячи людей работают над частями общей системы. Лидеры Поезда Решения должны обеспечивать, чтобы суммарная работа давала единую ценность и продвигала решение к общей цели.
Время Потока измеряет интервал, за который Капабилити и Эпики на уровне решения проходят все шаги рабочего процесса в Канбан системе. Метрика показывает способность Поездов (ART) и команд доставлять результаты в соответствии с общими целями и служит ключевым индикатором для планирования.
Поскольку Поезда (ART) внутри Поезда Решения выполняют и самостоятельную работу, которая в итоге вносит вклад в общую ценность Поезда Решения, лидеры Поезда Решения могут отслеживать время потока:
- на уровне каждого Релизного Поезда (ART),
- на уровне Поезда Решения в целом (агрегация).
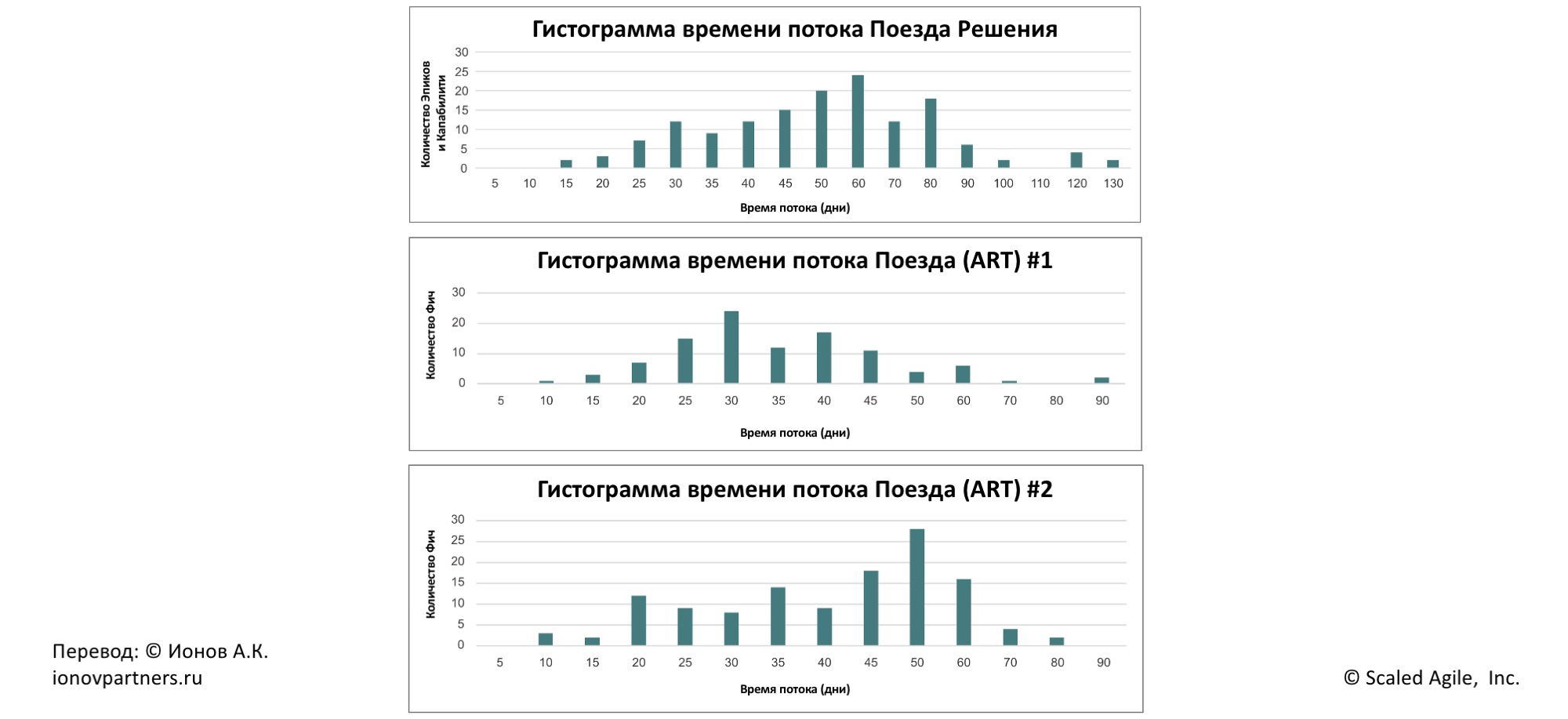
Рис. 6. Время потока Поезда Решения агрегирует время потока каждого ART.
Загрузка Потока (Flow Load)
Жёсткие сроки часто подталкивает руководство «загрузить» в систему ещё больше работы. Но избыточная нагрузка увеличивает, а не уменьшает время потока. Поэтому лидерам Поезда Решения важно в первую очередь фокусироваться на завершении уже начатой работы.
Чтобы видеть динамику загрузки во времени, измеряйте и анализируйте поток с помощью Кумулятивной Диаграммы Потока (Cumulative Flow Diagram, CFD). Этот инструмент помогает понять, как работа распределена по стадиям процесса и где накапливается незавершённая работа (рис. 7).
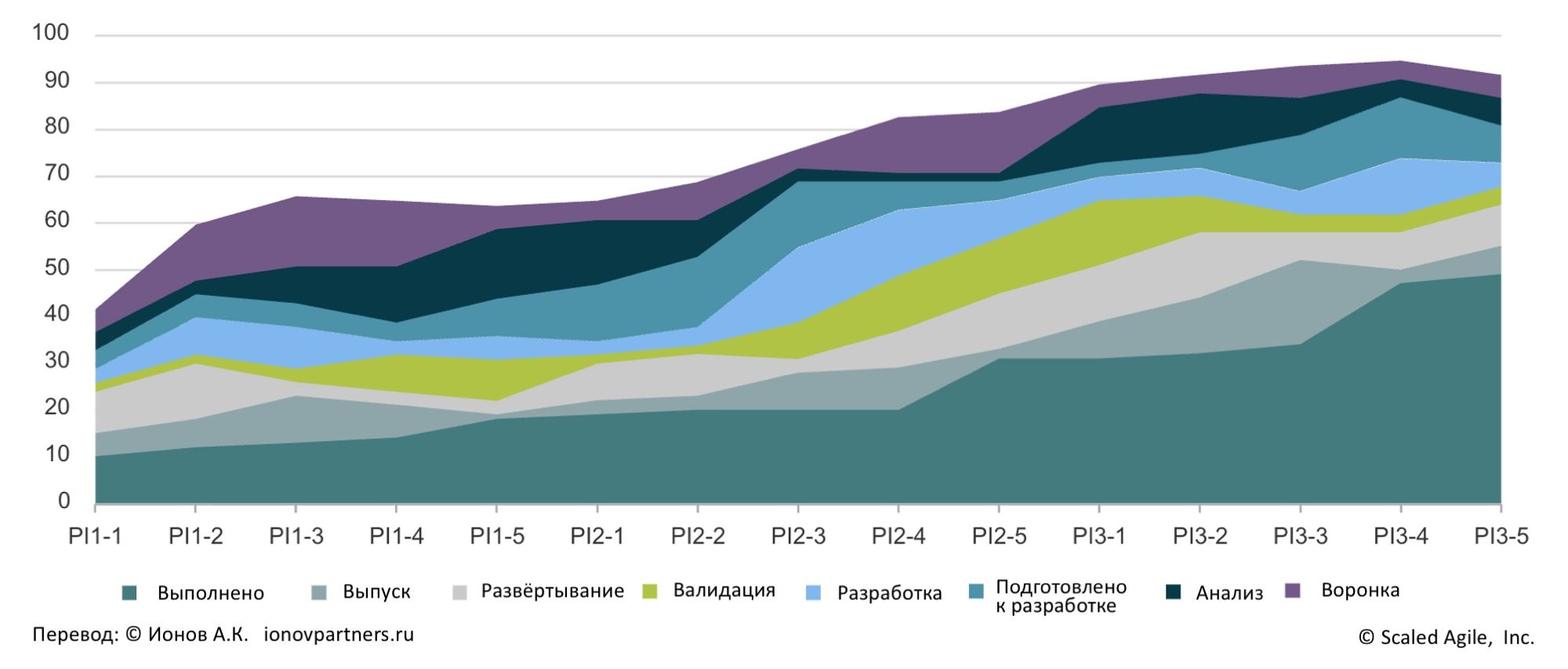
Рис. 7. Кумулятивная диаграмма потока показывает работу в системе на разных стадиях во времени.
Распределение Потока (Flow Distribution)
Разработчики крупных систем часто не могут полностью опереться на решения из открытых источников и готовые «из коробки» решения для инфраструктуры. Даже если могут – обычно требуется значительная доработка. Появляются дополнительные существенные риски, которые нужно прорабатывать как часть беклога.
Это означает, что лидеры Поезда Решения должны обеспечивать баланс между работами разных типов, приоритизируя и распределяя усилия между ними:
- Фичами
- Энейблерами
- поддержкой/обслуживанием
На рисунке 8 показано, как распределение потока по этим типам работ меняется во времени. Лидеры используют эту информацию, чтобы поддерживать здоровый баланс – без перекоса, который в итоге ломает скорость и предсказуемость доставки.
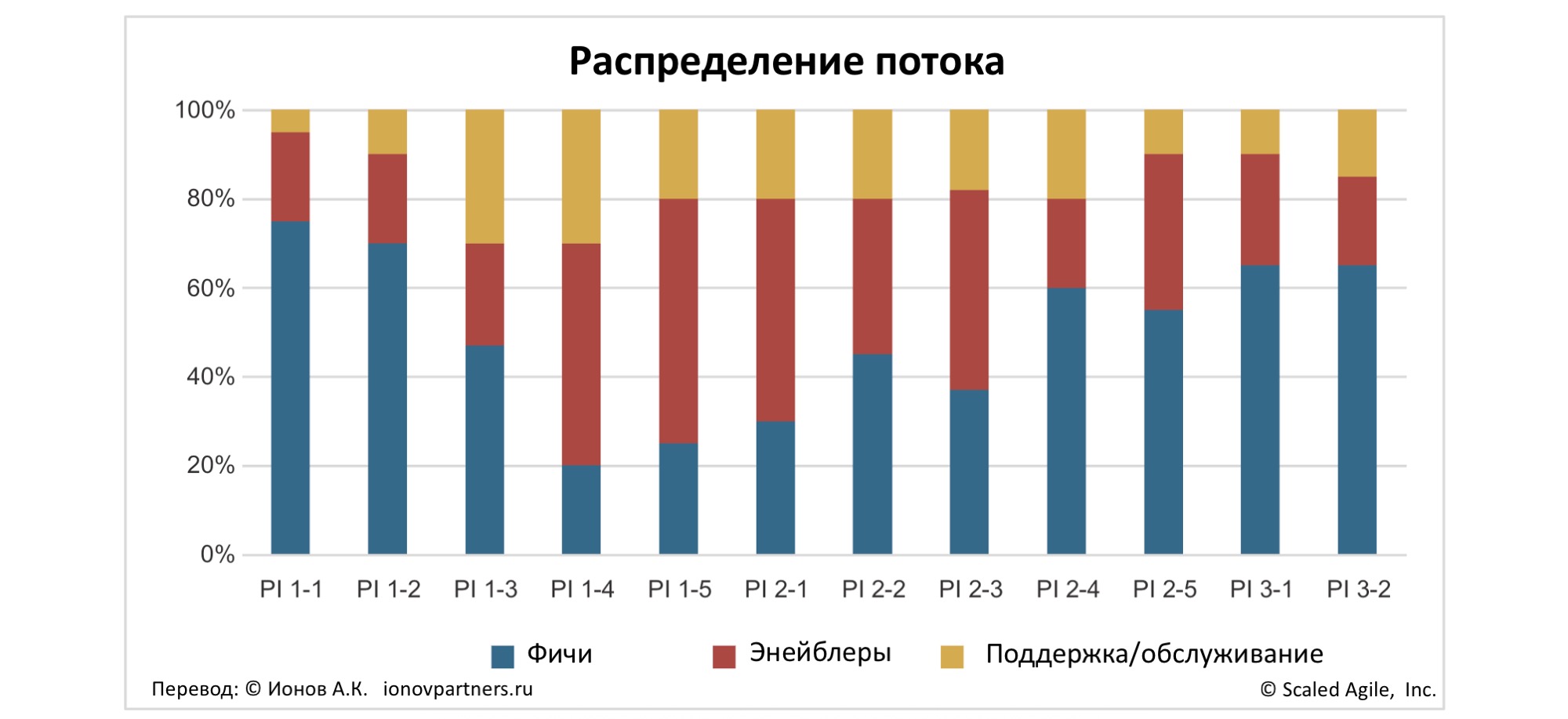
Рис. 8. Типы работ в системе должны быть сбалансированы во времени.
Краткие вопросы-ответы:
1) Что такое Поток Крупного Решения или Поток Поезда Решения в SAFe?
Это способность Поезда Решения (Solution Train), состоящего из нескольких Релизных Поездов (ART) и при необходимости поставщиков, обеспечивать непрерывную доставку ценности через регулярную интеграцию и выпуск Возможностей (Капабилити).
2) Чем Поток Поезда Решения (Solution Train Flow) отличается от Потока Релизного Поезда (ART Flow)?
Поток Релизного Поезда описывает поток внутри одного Релизного Поезда (обычно на уровне Фич и команд), а Поток Поезда Решения – системный поток на уровне всего решения, где происходит управление ключевыми зависимостями, интеграцией и осуществляется координация работы нескольких Релизных поездов и, возможно, поставщиков.
3) Что считать незавершённой работой (НЗР, WIP) на уровне Поезда Решения и зачем её ограничивать?
Незавершённая работа (WIP) – все начатые элементы, которые ещё не доведены до состояния «Выполнено» (Капабилити и Эпики в соответствующих Канбан системах, зависимые работы Поездов (ART) и поставщиков). Ограничение WIP снижает очереди и переключение контекста и обычно сокращает метрику «Время Потока».
4) Какие метрики потока важнее всего для Поезда Решения?
Время потока (сколько проходит элемент через процесс), загрузка потока (сколько работы одновременно в системе), распределение потока (баланс типов работ: фичи/энейблеры/поддержка).
5) Как измерять время потока на уровне Поезда Решения?
Фиксируйте старт/финиш прохождения Капабилити/Эпика по стадиям Канбан системы Поезда Решения (Solution Train Kanban) и агрегируйте данные по Релизным поездам (ART), чтобы видеть системное время прохождения и его вариативность.
6) Как читать кумулятивную диаграмму потока (Cumulative Flow Diagram, CFD) и находить узкие места?
Если на CFD «полоса» конкретной стадии расширяется, там накапливается незавершённая работа (НЗР, WIP) – это сигнал о наличии очереди или узкого места. Цель – стабилизировать накопления через ограничения НЗР (WIP), увеличение ёмкости или упрощение этапа.
7) Как обычно устраняют узкие места в крупных решениях?
Увеличивают ёмкость в узком месте (люди/навыки/среды/автоматизация), перераспределяют работу/приоритеты, подключают поставщиков или меняют правила принятия решений, чтобы согласования не тормозили поток.
8) Как снизить зависимости между Поездами (ART) и поставщиками?
Через модульную архитектуру, организацию вокруг доменов, кросс‑функциональность, минимизацию передач и раннее выравнивание по интерфейсам/контрактам интеграции.
9) Почему «быстрая обратная связь» критична для Поезда Решения и как её обеспечить?
Потому что поздняя обратная связь в больших системах приводит к дорогой переделке. Получение быстрой обратной связи обеспечивается «коротким путём» к клиентам/заинтересованным лицам, частой интеграцией, CDP и практиками встраивания качества.
10) Какие устаревшие практики чаще всего ломают поток и что делать?
Жёсткая этапность выполнения (Stage‑gate governance), EVM/WBS поверх Agile, фиксированные контракты, локальные KPI, низкая прозрачность поставщиков, поздний V&V/комплаенс. Решение – раннее и регулярное вовлечение комплаенса/качества/релиз‑функций и пересмотр политик под Lean‑Agile поток.
Оригинал: Scaled Agile, Inc. (вендор), статья «Solution Train Flow» (от 09.10.2023). Материал не является официальным переводом.
Перевод и адаптация: Алексей Ионов, Lean-Agile коуч организаций, Advanced SPC, Ионов и Партнеры.
Почитать дополнительно:
- Управление Потоком Ценности
- Принцип #6 – Обеспечить непрерывный поток ценности
- Поток Команды
- Поток Поезда (ART)
- Поток Поезда Решения (Крупного Решения)
- Поток Портфеля
- Ускорение Потока с помощью SAFe
- Коучинг Потока
© «Ионов и Партнеры» (ИП Ионов Алексей Константинович), 2018-2025. Все права защищены. Цитирование материалов и размещение ссылок на материалы для формирования сторонних баз знаний, рубрикаторов или агрегаторов допускается только с письменного согласия «Ионов и Партнеры».
SAFe® and Scaled Agile Framework® are registered trademarks of Scaled Agile, Inc.