Сторипоинты: что это и как применять в организации?
Автор статьи: Алексей Ионов, Advanced SPC, основатель компании «Ионов и Партнеры».
Кратко о статье
В этой статье мы с вами разберём вопрос, с которым я регулярно работаю и с командами, и с лидерами организаций: «Что такое «сторипоинты» (Story Points) и как использовать их так, чтобы они помогали управлению, а не превращались в «новую версию» человеко-часов?».
Ниже я постарался описать основные моменты в максимально прикладном ключе – с примерами из реальной практики внедрений. На примерах обычно лучше всего видно, где подход действительно работает, а где начинает буксовать и, порой, даже разрушать выстраиваемую адаптивную модель управления.
Почему вокруг оценок в Agile так много путаницы?
Если изучать разные источники (в интернете и тематической литературе), вы увидите достаточно неоднозначную картину: определения и рекомендуемые правила использования относительных оценок часто существенно отличаются и иногда прямо противоречат друг другу.
На практике есть нюанс, который в «книжных» описаниях часто упускают: даже когда рекомендация выглядит логично, при попытке применить её в действующей организации возникают вопросы:
- как это заработает не в одной команде, а в десяти (ста)?
- как связать оценки с дорожной картой, когда бизнесу нужны прогнозы?
- что делать с бюджетированием, учётом, контролем, аудитом?
- как избежать того, что новый подход к оценке станет просто «скрытыми человеко-часами»?
Цель, которую я преследую, работая с клиентами достаточно проста: новый подход к оценке должен помогать организации достигать бизнес-целей. Если же используемые новые подходы начинают мешать, это значит, что выстроена неправильная практика – даже если она «по книжке» она выглядит корректной.
Откуда возникла потребность в альтернативном подходе к оценке работы?
«Классическая» оценка: человеко-часы и нормирование

Классическое проектное управление опирается на нормирование величин. Если мы говорим о выполнении работы – это прежде всего человеко-часы. Логика здесь такая:
- мы достаточно точно заранее понимаем содержание работы, а это означает, что
- мы можем достаточно точно оценить длительность выполнения этой работы экспертно-расчётным методом.
И такой подход действительно работает, но при одном условии: работа должна быть повторяемая и стандартизированная (содержащая одинаковый набор операций, сущностей, элементов, событий, исполнителей и т.д.).
Примеры, где человеко-часы работают:
- конвейерная работа, где шаги и элементы полностью повторяются;
- многократно повторяемая обработка типового пакета документов по известной процедуре;
- серийные повторяющиеся операции в поддержке с фиксированным регламентом.
Имея некоторую историю выполнения такой работы (проведённый эксперимент с соответствующей доказательной базой) мы можем вывести «норму» и «отклонения от нормы», которые дальше лягут в основу нашей оценки.
Разработка нового: почему человеко-часы и нормирование перестают работать?
Как только мы переходим к созданию нового – продукта или решения, интеграции, новой функциональности, бизнес-процессов – нормирование перестаёт быть надёжным инструментом. Вы спросите «почему?».
Потому что всегда при создании чего-то нового или при выполнении операции, которая хотя бы немного будет отличаться от предыдущей, у нас всегда появляется «невидимая» часть. Например:
- понять, что именно нужно сделать на практике (а не «по документу»);
- выяснить детали, которые не прописаны в требованиях;
- принять (придумать) архитектурные/дизайнерские решения;
- договориться с соседними системами и командами;
- снять ограничения по данным, доступам, средам, тестированию.
Пример из типичной ИТ-разработки
Получено требование: «Добавить фильтр по статусу в отчёте». На бумаге оно выглядит как «простая мелочь». Но, как только её начинают реализовывать, выясняются нюансы:
- статусы в разных системах называются по-разному;
- отчёт строится на витрине, витрина обновляется раз в сутки;
- в UI нужно менять не только фильтр, но и правила отображения;
- тестирование требует пересчёта данных;
- нужен доступ к источнику, которого у команды нет;
- и т.д.
И вот уже «15 минут» по мнению менеджера, которые «с боем» запланированы как «4 часа работы», превращаются в «мы неделю только выясняли со смежными подразделениями, что вообще считается статусом»…
Что происходит, когда организация свою разработку всё равно оценивает в часах?
Все или подавляющее большинство систем управления предусматривают какую-то иерархию (пусть даже экспертную или лидерскую), в которой часто возникает желание «дожать»: «Ну вы же профессионалы! Напишите сколько часов. Точно. И несите за это ответственность!».
Дальше запускается типовой конфликт:
- исполнитель старается «перезаложиться» (иначе его накажут за отклонения);
- заказчик/менеджмент старается «ужать» (иначе бюджет не сойдется).
Предсказуемые эффекты:
- споры и торг вместо разговора о ценности и рисках;
- демотивация обеих сторон;
- рост контроля и согласований;
- ориентация на «закрыть часы» вместо «сделать хорошо».
Как бы грустно это не звучало, но таким образом, стремясь к точности оценок там, где её изначально нет, мы фактически получаем не точность, а конфликт и бюрократию.
Здесь нужно сразу оговориться. Как управленец я прекрасно понимаю, что организация не может жить без оценок. Бизнесу нужно понимать:
- во что нам выгоднее инвестировать?
- когда можно планировать запуск?
- как будет выглядеть дорожная карта продукта?
- как принимать решения о приоритетах?
Решение: относительная оценка
Почему относительная оценка практичнее?
На практике мы вряд ли сможем уверенно сказать: «Эта работа займет точно 17 часов». Но мы в подавляющем большинстве случаев при этом сможем ответить на вопрос, что сложнее из двух вариантов работы: «Это скорее всего в два раза сложнее, чем то, что мы делали на прошлой неделе».
Относительная оценка именно так и работает: сравниваем, а не «измеряем линейкой, которой у нас нет».
Простой пример
Если вы не бариста, вы не скажете точно, сколько миллилитров в чашке «на глаз».
Но вы точно скажете: «Эта чашка больше, чем та».

Ровно то же самое происходит и в разработке: в подавляющем большинстве случаев команда может уверенно сравнивать задачи между собой, не погружаясь в точную оценку каждой из них – особенно если речь идёт о небольших задачах, которые в глазах команды укладываются в несколько дней работы.
Что такое сторипоинт/пункт/балл оценки историй (и чем он не является)?
Пункты оценки историй (Сторипоинты, сокращённо «сп», можно также использовать термин «баллы оценки историй») – условная единица относительной оценки «сложности» выполнения небольшого законченного элемента работы (истории) для конкретной команды.
Давайте сразу договоримся о важной аксиоме, которую ниже я постараюсь максимально раскрыть.
- Пункты историй (сторипоинты) никак не переводятся в часы по формуле, иными словами,
- никаких «1 сп = 8 часов» не существует и быть не должно.
Если вы как-то создадите формулу однозначного перевода сторипоинтов в человеко-часы, – вы сразу вернётесь к нормированию, только под другим названием, со всеми вытекающими негативными последствиями, которых мы хотим избежать. И способ не создавать такую формулу есть, об этом – ниже.
Как это можно объяснить руководителям?
Сторипоинты – это не «новый вид человеко-часов». Это способ, при котором команда нам говорит: «Вот это – маленькое, вот это – среднее, а вот это – большое», а мы потом, через фактическую скорость доставки, которую демонстрирует команда, можем получить прогноз и построить дорожную карту.
Из чего складывается оценка: 4 компонента

Предлагается смотреть на сторипоинты, как на одновременную совокупность нескольких факторов:
- Объём – сколько работы по ощущениям нужно сделать этой команде
- Сложность/комплексность – сколько взаимосвязей, вариантов, «подводных камней» мы видим?
- Знание – насколько это похоже на то, что эта/наша (!) команда уже делала?
- Неопределённость – насколько нашей команде в принципе понятна эта работа или сколько ещё уточнений потребуется по ходу выполнения?
Примеры, когда фактор «знание» резко меняет оценку
- Для команды А интеграция с Kafka – рутина: они это делают ежемесячно.
- Для команды Б Kafka – «чёрный ящик» (а что это?), нужно проводить исследования и эксперименты.
Одна и та же формулировка в беклоге, но оценка будет разной – и это нормально!
Кто оценивает: важное правило, которое часто нарушают
Оценку делает та команда, которая будет выполнять эту работу. Не архитектор или лид «сверху», не PMO, не руководитель разработки, не «экспертная комиссия».
Если работу будет делать другая команда – оценка может быть другой. В адаптивной модели управления мы не имеем права требовать одинаковых оценок от разных команд.
На практике также крайне важно, чтобы все на организационном уровне, а в SAFe – это VMO, LACE, RTE и Скрам мастера / Коучи команд, одинаково понимали правила использования относительной оценки и сопровождали работу всех участников портфеля при появлении сложностей, проблем или сопротивления.
Шкала оценок: от «футболок» к Фибоначчи
Иногда на старте используют грубую шкалу «размеров футболок» или «оценку в майках»:
- XS / S / M / L / XL / XXL

Это полезно как разминка – чтобы команда начала сравнивать. Либо, если мы сравниваем действительно большие элементы работы, – чтобы дифференцироваться от тех оценок, которые на уровне отдельных небольших элементов (историй) команды будут давать в цифрах. В последнем случае полезно также под каждым размером «майки» понимать некоторый диапазон величин на уровне команды.
На уровне команды, там, где осуществляется реальная и наиболее точная (но всё равно примерная) оценка, применяют модифицированную шкалу Фибоначчи:
которая начинается с 1, 2, 3, 5, 8, 13 и далее следуют уже не числа Фибоначчи, а «психологически большие» величины в 20, 40, 100 и «бесконечность». Такая шкала, с одной стороны, позволяет сохранить «примерность» оценки, а с другой – лучше отражает рост неопределённости (и ошибки!) в оценках по мере увеличения задач.
Что такое «1 сторипоинт»? Практический способ калибровки
Первое, что нужно сделать для начала использования относительных единиц оценки, – договориться, что команда считает «одной штукой», «единицей» сложности. И здесь на практике обычно начинаются сложности, поскольку, с одной стороны, зачастую менеджмент пытается «взять вопрос в свои руки» (что неприемлемо!), но, с другой стороны, Скрам мастера, Аджайл коучи и возможно другие «наставники» не дают командам простых и понятных идей, чтобы они сами начали договариваться об «эталоне» для последующей оценки.
Когда мы работаем в корпоративном масштабе, появляется ещё одна проблема, которую нужно решить. С одной стороны, нам необходимо, чтобы команды сами оценивали свою работу, но с другой – если единицы этих оценок будут радикально, в 3-5-10 или более раз отличаться, у нас не получится оперировать единой пропускной способностью для команды команд.
Нам нужно решение, которое оставляет процесс на стороне команд – а не менеджмента или архитектуры, – но при этом обеспечивает, чтобы различия в используемых командами условных величинах не превышали двухкратный диапазон от команды к команде. Это позволит нам затем суммировать оценки и показатели пропускной способности, получая данные, которые можно использовать на большем масштабе.
Подход, который хорошо работает в корпоративной среде
Как мы решили выше, мы категорически не можем привязывать размерность сторипоинта к человеко-часам. Но при этом можем договориться, что все команды будут использовать единое правило определения элемента работы (истории) на одну единицу, с которой будут сравниваться другие работы. При этом фактическое количество часов, которое команда сможет потратить на такую работу, будет отличаться. Такая схема существует и может хорошо работать.
Для начала мы договоримся, что в нашей организации используется следующий принцип, который остаётся неизменным, и менеджмент не сможет дополнять его какими-либо новыми условиями. Это будет «принцип определения истории со сложностью «1», и его мы установим следующим образом:
1 сторипоинт (пункт/балл оценки истории) – это законченная работа (история), которую команда способна сделать примерно за один день непрерывной работы, доведя до «Выполнено» по своему Определению Выполненности/Завершённости (Definition of Done, DoD).
Обращаю внимание:
- Мы не указываем, сколько человек должно быть задействовано;
- Мы не знаем, как именно эти люди будут работать и в какой комбинации (частично параллельно, частично последовательно, где-то в парах или группе);
- Мы не знаем, сколько часов они потратят: это не человеко-день, не сумма часов и формула не может быть определена;
- Это не «8 часов разработчика» и не «8 часов всей команды»;
- Это работа, которую, делая непрерывно, мы (команда) полностью выполним примерно за один день в офисе.
Давайте разберём три примера, каждый из которых может быть оценен как «одна единица» работы.

- Пример 1. Для выполнения истории нам нужны 3 участника команды: Аналитик уточнил и сформулировал критерии, разработчик реализовал, где-то члены команды работали параллельно или вместе, тестировщик проверил, поправили дефекты, приняли, история стала «Выполнена».
- Пример 2. Для выполнения истории нам нужно два человека из команды: Два инженера по очереди продвигали задачу, быстро синхронизировались, один из них организовал закрытие в статус «Выполнено».
- Пример 3. 1 сторипоинт сделал один человек за день: Один участник непрерывно работал и довел до «Выполнено».
Как можно увидеть, количество часов, которые участники команды фактически потратили на работу, будет отличаться, и это нормально. Ключевой вопрос – не «сколько часов потребуется?», а сколько «астрономического» рабочего времени команды потребуется на выполнение, при условии, что:
- будет соблюдаться непрерывность потока работы относительно этой истории: сама работа будет выполняться непрерывно, но каждый участник выполнения этой работы не сможет и не должен работать над ней непрерывно, если это только не один человек;
- произойдёт завершение истории по критериям приёмки этой истории и общим Определениям завершённости (DoD) команды.
И если всё перечисленное выше займёт примерно один день, то такую работу мы оцениваем как «сложность работы = 1».
На обучении я часто использую следующий вопрос, когда меня просят описать, как происходит оценка сложности командой: «Если мы условно «закроем» нужных людей в комнате и попросим их не отвлекаться на другие задачи, но не будем требовать 100% загрузки по минутам – смогут ли они сделать это примерно за день? Если да – это хороший кандидат на 1 пункт/балл выполнения истории (сторипоинт)».
Очень надеюсь, что из всего вышесказанного у читателя уже не остаётся сомнений в том, что:
- нет и не может быть формулы для перевода человеко-часов в сторипоинты;
- «один астрономический день работы команды» – это якорь калибровки, а не способ оценки или взятия обязательств (об этом мы ещё поговорим ниже);
- сложность работы в «1» для каждой команды будет своя, поскольку экспертиза и опыт у команд разные;
- такое правило, оставляя команде максимум свободы, позволяет сделать так, чтобы размерность оценки сложности у максимально похожих команд отличалась меньше, чем в разы или на порядок;
- правило по определению истории на «1» обрабатывается командой и только командой, это не может быть менеджер, архитектор и т.д.;
- каждая команда может выбрать или сформулировать абсолютно любые истории на «1»;
- за корректность работы процесса отвечает Скрам Мастер / Коуч команды как «защитник» Lean-Agile подходов к организации работы.
Практика: «эталонные» истории
На практике у команд может возникнуть сложность с относительной оценкой, поскольку они могут работать с разными техническими стеками или типами работ. Поэтому, в дополнение к сказанному выше, я предлагаю таким командам совместно выполнить следующие шаги, чтобы вместе осознать подход и взять на себя ответственность за принятые решения:
- проговорить правило определения работы сложностью «1», чтобы все его понимали одинаково;
- обсудить основные виды/типы историй, с которыми команда обычно работает (например, UI-истории, бэк и инфраструктура);
- для каждого основного типа работы выбрать из беклога, а если в беклоге таких нет, сформулировать эталонные истории на «1» (например, «1 SP для UI – это…» и «1 SP для DevOps – это…»);
• зафиксировать их как «калибровку» (без бюрократии – просто как память команды);
• договориться: если у кого-то из команды в будущем возникнут сомнения, что какая-то работа действительно «1» по согласованному правилу – вернуться к этому обсуждению и, возможно, изменить формулировки «эталонных» историй.
Почему предлагаемый подход помогает на уровне организации?
Мы определили, что размерность в сторипоинтах разных команд не будет идентичной – и не должна. Но если на практике команды используют единый подход к калибровке, то различия между командами не будут радикальными. Это даёт организации управленческий эффект:
- Легче обсуждать объёмы на уровне фич и релизов, когда мы можем суммировать оценки разных команд, без возврата к «точным часам»;
- Проще выстраивать ожидания бизнеса через прогнозы по фактической доставке;
- Позволяет снизить риск ловушки: «мы внедрили относительную оценку, но получили те же споры про сроки, которые не соблюдаются».
Ценность оценки в сторипоинтах нельзя рассматривать отдельно от планирования работы
Сторипоинты сами по себе – это язык сравнения сложности. Оценка ≠ план. И здесь у менеджмента часто возникает обоснованный вопрос – а где и как мы начинаем планировать на основе новых оценок? Давайте этот момент разберём. План в гибких подходах управления появляется тогда, когда мы связываем оценку с двумя величинами:
- Пропускная способность (velocity) – средняя фактическая «скорость» доставки в условных величинах для организационной единицы (команда, поезд, поток, портфель) за стандартный шаг каденции (итерацию или интервал).
- Ёмкость (capacity) – количество условных единиц работы, которую организационная единица (команда, поезд, поток, портфель) может выполнить за конкретный (с известными датами начала и окончания) шаг каденции (итерацию или интервал).
Рассмотрим эти величины и их применение подробнее, как оно рекомендуется в SAFe, для масштаба команды и, где применимо, поезда.
Средняя пропускная способность
Пропускная способность (velocity) команды – это среднее количество сторипоинтов этой команды, которое они в среднем фактически завершают за итерацию (спринт).
- Таким образом, пропускная способность для одной команды будет равна общему количеству сторипоинтов, которое команда выполнила за интервал, делённому на 4, если в организации установлен интервал планирования (PI) с четырьмя рабочими итерациями.
- Пропускная способность всего поезда (Agile Release Train, ART) за одну итерацию будет равна сумме средних пропускных способностей всех команд этого поезда за итерацию.
Зачем это нужно?
Пропускная способность нам нужна прежде всего для построения дорожных карт и ответов на такие вопросы, как: «в каком квартале мы вероятнее всего доставим вот этот функционал?» или «сколько итераций потребуется на вот такой набор фич?».
При этом пропускная способность, являясь усреднённой величиной, не подходит для ежедневного планирования конкретной итерации или интервала поезда. Для итераций нужна более прикладная оценка – ёмкость (capacity).
Ёмкость команды на конкретную итерацию
Ёмкость (capacity) команды – это сколько сторипоинтов команда планирует выполнить именно в эту итерацию (которая начинается и заканчивается в конкретные даты), учитывая реальность:
- отпуска и отгулы,
- праздники,
- дежурства,
- заранее известные «выключатели» рабочего времени.
Зачем это нужно?
Ёмкость – это величина для:
- планирования итерации;
- подготовки и проведения мероприятия планирования Интервала (PI Планирования).
Логика простая: сначала каждая команда самостоятельно считает свою ёмкость, затем под эту ёмкость «набирает» истории, после чего обязательно валидирует выполнимость (иначе ёмкость превращается в «магическую цифру на бумаге»).
Как команда считает ёмкость: стартовое правило
Когда команда уже работает какое-то время, её участники могут совместно предположить количество сторипоинтов, которые они смогут «закрыть», выполнив истории за итерацию.
Но когда команда только сформирована или заметно изменена, исторических данных либо нет, либо на них уже нельзя полагаться. В этом случае для приблизительного (с последующей корректировкой!) определения количества сторипоинтов, которые команда потенциально сможет выполнить, используется эмпирическое (выведенное на практическом опыте) правило:
8 сторипоинтов на двухнедельную итерацию на одного участника команды без учёта Владельца Продукта и Скрам мастера / Коуча команды.
Давайте рассмотрим пример, чтобы было понятно на цифрах.

Возьмём Agile-команду из 7 человек:
- 3 разработчика
- 1 тестировщик
- 1 аналитик-технический писатель
- 1 Владелец продукта
- 1 Скрам мастер / Коуч команды
Убираем из расчёта Владельца Продукта и Скрам мастера, итого – считаем 5 человек.
Оценочная «идеальная» ёмкость двухнедельной итерации такой команды (под «идеальностью» мы понимаем отсутствие отгулов, отпусков, отсутствий на работе и праздничных дней) составит 5 человек x 8 сп / итерация = 40 сторипоинтов.
Чтобы от «идеальной» оценочной ёмкости перейти к «практической» оценочной ёмкости, из неё нужно вычесть частично или полностью отсутствующих в эту итерацию участников команды.
Как учитывать отсутствие (простое практическое правило):
- на 1 день отсутствия одного участника в двухнедельной итерации мы вычитаем 1 сторипоинт. Например, если «идеальная» ёмкость была 40 сп, но один человек берёт отгул на 1 день – получаем 39 сп.
- если вся команда отсутствует день (например, это праздник), то вычитается количество участников (по 1 сп на каждого) без двух ролей (Владельца Продукта и Скрам Мастера). Например, для нашей команды в 7 человек, без Владельца Продукта (ВП) и Скрам Мастера (СМ) будет 5, и мы вычитаем 5 сп из идеальной ёмкости: 40 сп – 5 сп = 35 сп на итерацию.
- Если сотрудник участвует в работе «разработческой» части команды лишь частично (например, на 50% совмещает эту работу с ролью Владельца Продукта или Скрам Мастера), то на него закладывают половину сторипоинтов, – то есть не 8, а 4 на итерацию. При этом иные дробные значения не применяются, кроме того, если речь не о ролях ВП или СМ, такой участник не может одновременно входить более чем в одну команду.
Таким образом, суммарно с 1 отгулом одного участника и 1 государственным праздником «практическая» оценочная ёмкость для этой команды составит 34 сп на эту итерацию.
Это предварительная рабочая цифра, на которую наша новая команда будет набирать истории в итерацию. А затем, уже опираясь на конкретику и статистику работы в нескольких итерациях, команда сможем уточнить это стартовое правило.
Хотелось бы тезисно оговорить важные моменты, чтобы избежать недопонимания в работе со стартовым правилом расчёта ёмкости команды.
- «Правило 8 сп», как и вообще сторипоинты, не могут стать «нормой производительности». Правило используется только для того, чтобы на старте работы команды, при отсутствии исторических данных, предположить ответ на вопрос «сколько сторипоинтов, возможно, сделает эта команда за итерацию».
- Получив статистику работы в текущем составе в течение нескольких итераций, команда на основе описанного выше «правила 8 сторипоинтов» вырабатывает собственный способ определения ёмкости команды, который может отличаться от исходного правила или содержать дополнительные условия. Это отличает «правило 8 сторипоинтов» от правила определения сложности истории на «1», которое не подлежит дальнейшему уточнению, может только меняться сама история (истории), выбранная командой как «эталон».
- Только команда определяет количество сторипоинтов, которое она сделает за конкретную итерацию, это не может делать руководитель, архитектор или кто-либо ещё.
- Сторипоинты не выполняют функцию давления на команду, как это происходит обычно с человеко-часами. Иными словами, никто за рамками команды не может контролировать или требовать выполнения какого-либо количества сторипоинтов за единицу времени. В Agile и SAFe считается достаточным, что команда берёт на себя обязательства за достижение целей итерации и целей на интервал планирования (PI).
- Правило оценки стартовой ёмкости является эмпирическим, и оно не может быть дополнено какими-либо «стандартными для нашей компании/поезда» дополнительными формулами или условиями. В конечном счёте расчёт количества сторипоинтов на итерацию является внутренним вопросом каждой команды и их собственным «правилом».
- Попытка на основе рассматриваемого стартового эмпирического правила вывести формулу пересчёта сторипоинтов в человеко-часы делает бессмысленным использование сторипоинтов и относительной оценки, возвращает «классические» конфликты вокруг оценок и работает против эффективности и адаптивности организации.
- После «набора» историй на рассчитанную ёмкость команда должна провести валидацию на основе конкретных историй и экспертизы участников команды. По итогам валидации ёмкость может быть пересчитана командой (об этом – ниже).
- Если какую-либо работу делает Владелец продукта (например, участие в исследовании) или Скрам мастер / Коуч команды (например, улучшение организации работы команды), такие истории в их части могут находиться в беклоге с оценкой сложности «0», поскольку эти роли не учитываются в ёмкости.
- Если команда занимается поддержкой, обычно речь идёт о распределении (аллокации, бронировании) ёмкости под соответствующие классы/типы работ в общей ёмкости команды, поскольку истории поддержки/обслуживания заранее неизвестны.
- Поскольку и оценка историй, и оценка ёмкости находятся в руках команды (и это правильно!), пропускная способность и ёмкость не подходят для использования в качестве KPI или организации соревнования между командами.
Разговор про ёмкость команды будет неполным, если мы не рассмотрим, как производить валидацию расчётной ёмкости и отдельных историй при планировании работ командой. Здесь мы не будем рассматривать все тонкости проведения мероприятия Планирования итерации – об этом можно прочитать отдельную статью «Планирование Итерации»
Три шага планирования итерации с точки зрения использования сторипоинтов
Шаг 1. Вычислить ёмкость
Команда считает свою «идеальную» и затем плановую оценочную ёмкость на конкретную итерацию. Например, 40 и 34 сп.
Шаг 2. Набрать историй примерно на эту ёмкость, не превышая её
Например, набрали 12 историй суммарно на 34 сп. Во время определения этих историй каждый участник команды предварительно фиксирует, что именно в каждой из историй будет делать он/она. Это важно для следующего шага.
Шаг 3. Провалидировать выполнимость (обязательный шаг)
Потому, что «набрали на 34 сп» не означает «сделаем на 34 сп».
Для валидации (проверки выполнимости) команда должна совместно ответить на три практических вопроса:
1. Сможет ли каждый из нас реально выполнить «свою» часть работы?
В процессе обсуждения историй в команде предварительно зафиксировали, кто потенциально будет участвовать в каждой истории (аналитика, разработка, тестирование, приёмка и т.д.). На основании этих знаний каждый участник смотрит на весь набор историй и проверяет: «а я физически успеваю поучаствовать там, где от меня зависят блокирующие элементы?» и «а я физически это всё в принципе смогу сделать за итерацию (2 недели)?».
2. Ровная ли загрузка по людям?
Классическая проблема планирования заключается в том, что команда набирает истории на свою ёмкость, но оказывается, что во многих историях критически нужны один или два участника команды. Это будет означать следующее: такие члены команды станут «бутылочным горлышком», и итерацию просто не удастся выполнить.
Также может произойти обратная ситуация, когда команда «заполнила ёмкость», но часть команды не видит вообще «своей» работы в отобранных историях.
Если одна из подобных ситуаций происходит, команда может предпринять следующие действия:
- не брать часть историй (переформулировать некоторые истории со своим Владельцем Продукта),
- перераспределить участие внутри команды, если это возможно,
- обсудить передачу знаний (обычно это не решается за одну итерацию, но может стать решением на будущее, если ситуация повторяется).
3. В целом, сможет ли команда это сделать в этом объёме?
Бывает, что перегружены все. Если декомпозировать истории по какой-то причине проблематично, а их оценка выглядит корректной по мнению команды – значит, скорее всего, нужно корректировать плановую ёмкость и обновлять правила её расчёта для команды.
Именно регулярное выполнение валидации ёмкости позволяет со временем «настроить» своё правило расчёта ёмкости команды. При этом напомню, что правило «что такое 1 сп?» мы не меняем. А вот правило определения «сколько сторипоинтов мы реально делаем за итерацию?» команда может постепенно уточнять, используя исторические данные.
Здесь важно оговориться, что цель не в том, чтобы «угадать» точное количество условных единиц оценки, которое команда выполнит за итерацию. Цель – приблизить планирование к фактическим значениям настолько, чтобы оно стало надежным.
Возвращаемся к оценке: как команда оценивает истории?
Теперь давайте вернёмся, собственно, к оценке. Мы специально вначале проговорили, как команда использует значения ёмкости и уже существующие оценки, чтобы теперь, уже имея это понимание, рассмотреть, как команда оценивает истории и определяет корректность такой оценки.
Ранее мы договорились, что 1 пункт/балл сложности выполнения истории (сторипоинт) – это работа, которую, делая её непрерывно с любым (разным) количеством участников, команда завершит примерно за один астрономический рабочий день (в идеальных условиях, без отвлечений, без привязки к человеко-часам и без требования полной загрузки всех вовлечённых).
Если у нас есть такая согласованная внутри команды «эталонная» история (или истории), оцениваемую историю можно сравнить с «эталонной». Идея относительной оценки заключается в том, что команда вспоминает факторы, заложенные в эту условную относительную оценку (объём, сложность/комплексность, знания, неопределенность), и определяет, во сколько раз оцениваемая история сложнее той, которую мы приняли за «1».
При этом такое отличие может выражаться только в значениях специально разработанной для этого модифицированной шкалы Фибоначчи (1, 2, 3, 5, 8, 13, 20, 40, 100, ∞), никакие другие – тем более дробные – значения использоваться не могут.
Делается это для того, чтобы упростить обсуждение и ещё раз подчеркнуть примерный характер относительной оценки – мы эмпирически оцениваем сложность, но узнать точно, какая сложность была, можно только тогда, когда работа будет выполнена. И такие пост-обсуждения имеет смысл проводить в команде с целью повышения точности и согласованности оценки и работы в будущем.
На практике, особенно когда команда только начинает подобные обсуждения, участникам бывает достаточно сложно сразу начать думать в терминах относительной оценки. Чтобы «войти» в процесс, оценивая какую-либо историю, каждый участник, оценивая сложность, может задаться аналогичными вопросами, которые мы обсуждали, выбирая историю на 1 сп:
- Если мы условно «закроем» нужных людей для выполнения этой истории в комнате и попросим их не отвлекаться на другие задачи, но не будем требовать 100% загрузки – за сколько астрономических рабочих дней команды они эту работу, скорее всего, сделают с учётом объёма, сложности/комплексности, их знаний и неопределённости?
- К какой из цифр модифицированной шкалы Фибоначчи ближе всего получившееся количество астрономических дней работы команды?
- Теперь, если я посмотрю на историю, которую мы выбрали как «1», действительно ли оцениваемая работа во столько раз сложнее, или это значение ещё нужно скорректировать в большую или меньшую сторону?
- Как я обосную для своей команды, почему именно это значение я выбрал?
Здесь очень важная оговорка, которая защищает команды от управленческой ошибки:
Никто извне команды не может требовать «сделайте это за неделю», потому что story points – не плановый календарь и не часы. Команда в реальности может делать историю сколько угодно дней; единственное, под чем подписывается команда – это выполнимость итерации (спринта) в целом, и конкретно – достижение целей итерации и максимально возможное выполнение всех историй внутри итерации.
В Agile обязательства команды берутся на итерацию и формулируются как цель итерации. Сколько «реальных дней» заняла отдельная история – вопрос работы команды и не предмет требований извне. При этом, внутри команды могут быть любые договоренности, но озвученные наружу оценки не должны «автоматически» превращаться в сроки. Дополнительно прочитать статью о Целях Итерации
Как технически происходит оценка? Покер Оценки (Estimating Poker)
Поскольку оценка использует модифицированную шкалу Фибоначчи, со временем она будет проходить достаточно быстро: человеку сложно различать оценки по близким значениям (например 5, 6, 7 или 8), тогда как выбрать между «это больше похоже на 5 или на 8» значительно проще. При этом, справедливости ради, отмечу: к технике нужно привыкнуть, поэтому первые сессии оценки команды могут потребовать существенного времени на освоение техники и выработку договорённостей.
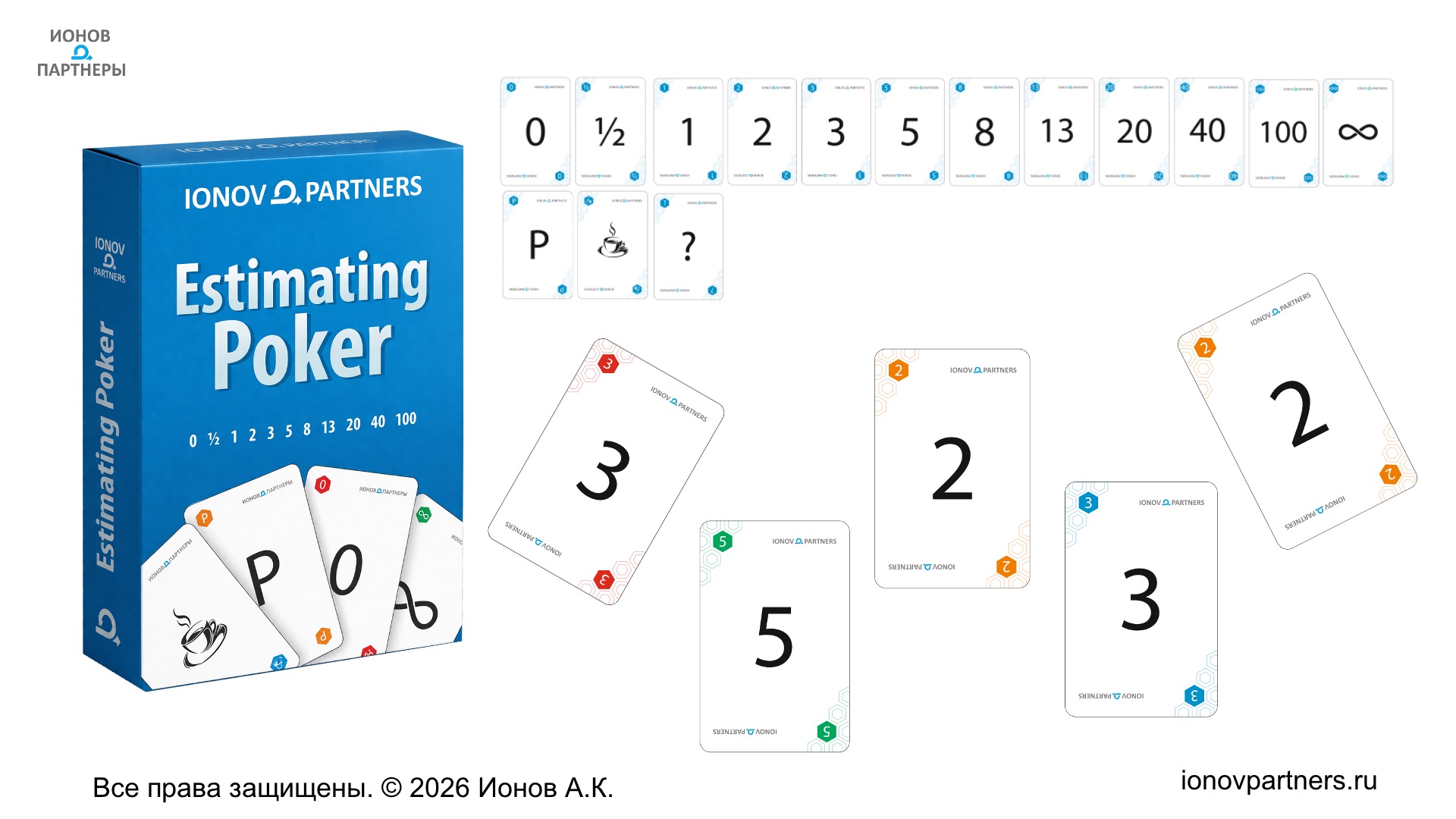
Колода карт
Типовая колода:
- Основные карты, используемые каждым участником для оценки: 1, 2, 3, 5, 8, 13, далее
- 20, 40, 100 – большие значения, под которыми подразумевается, что «скорее всего, мы ошибаемся» и «это надо прорабатывать и дробить на части позже».
- ∞ – «настолько большое/непонятное, что оценить сейчас нельзя».
- Также у участника команды на руках будут служебные карты: «½», «?», «℗» (парковка), «☕️» (кофе), иногда какие-то ещё.
Служебные карты: зачем они нужны?
- 0 – команде ничего не нужно делать или это работа не разработческой команды. Иногда 0 ставят на элементы, которые делает Владелец Продукта или Скрам Мастер (например, процессные улучшения).
- 1/2 (0.5) – удобно для мелких незапланированных работ: багфиксов, обслуживания. Когда 0 – неправда, а 1 – уже «слишком много». Обычно не применяется в плановой оценке, но используется для быстрой оценки срочных работ, поддержки и обсуждений после выполнения итерации.
- ? – «у меня критичный вопрос: без ответа на него я не смогу дать оценку».
- P (parking) – «предлагаю отложить оценку этой истории» (с аргументом почему).
- кофе – «хочу кофе», т.е. предлагается перерыв.
Как проходит раунд оценки?
Предлагаемая техника известна в научном мире как метод «Широкополосный Дельфи». Для работы Agile-команд техника была адаптирована в своё время известным экспертом и автором книг Майком Коном.
В определении оценок не участвуют Владелец продукта и Скрам мастер / Коуч команды, но они участвуют в самом мероприятии оценки. Владелец продукта – как главный эксперт и представитель бизнеса/клиента, который к тому же будет работу принимать. Скрам мастер / Коуч команды – как ведущий мероприятия, который также следит, чтобы правила его проведения соблюдались, и все участники были максимально вовлечены.

- Владелец продукта озвучивает историю, контекст и детали.
- Команда задаёт вопросы и уточняет детали. Предварительно здесь также может обсуждаться, кто из команды может быть задействован в выполнении этой истории.
- Когда у всех участников команды появляется понимание сложности истории, каждый участник выбирает одну карту из своей колоды. Эта карта показывает сложность выполнения истории в целом для всех участников команды, которые будут вовлечены. (Не допускается оценка «только моей части», это именно сложность для всей нашей команды).
- Все кладут по одной карте с оценкой сложности «рубашкой вверх». Если используется онлайн-средство, оно аналогично показывает, что участник выбрал карту, но не показывает какое значение выбрано.
- Все участники одновременно открывают карты и обсуждают различия. Часто здесь Скрам мастер просит тех, кто положил самую большую и самую маленькую по значению карты, объяснить свой выбор.
- Проводится второй, а иногда и третий раунд оценки. Далее участники обычно договариваются голосом, поскольку все позиции уже озвучены и карты, скорее всего, будут иметь максимально близкие значения.
Выбор карты «в закрытую», «рубашкой вверх», имеет важное значение для качества оценки. Дело в том, что, если показывать выбор сразу, менее опытные участники начнут – осознанно или нет – «равняться на авторитет» кого-либо в команде. Это как раз то, что мы хотим избежать, поскольку нам нужно независимое мнение каждого и нам важно, чтобы экспертиза и ответственность каждого участника команды росла в части понимания выполнения работы всей командой, а не только в рамках «своей части» или экспертизы.
Важное предостережение: не усредняйте автоматически!
Предлагаемая техника оценки является также протоколом обсуждения, поэтому важно, чтобы происходило именно обсуждение и итоговый выбор значения командой, а не автоматическое вычисление средней или средневзвешенной оценки. С автоматизацией может потеряться ценность самой оценки и важные детали работы, которые превратятся в «неожиданные» проблемы в будущем.
Например:
- большинство участников команды выбрали карту «3»,
- но один участник положил «5».
Правильное завершение – не округлённое до «3» среднее, а командное решение: либо 3, либо 5. И порой разумно взять именно 5, если на такой оценке настаивает человек, который видит обоснованный ключевой риск или действительно будет выполнять критическую часть этой истории.
Потом, когда работа будет сделана, мы с командой можем вернуться к этому обсуждению и зафиксировать на будущее, какое значение мы уже более уверенно выберем, когда будем делать что-то похожее.
Напомню ещё один важный принцип: оценивает та команда, которая будет делать эту историю (работу). Никакие «оценки менеджера» или «оценки другой команды» не заменяют оценку исполнителями, и такая оценка-переоценка может происходить многократно с получением новой информации и опыта.
Критерии приёмки и Определения завершенности (DoD)
Перед тем как команда начинает оценивать истории, обязательно проверьте два условия:
- У истории есть понятные критерии приёмки.
- Команда понимает и применяет свое Определение Выполненности/Завершённости (Definition of Done, DoD).
Это крайне важно, поскольку и критерии приёмки, и DoD напрямую влияют на:
- объём,
- риски,
- неопределённость,
а значит – на оценку, которую определяет команда.
В связи с этим есть практическая рекомендация: прежде чем приступать к оценке («играть в покер»), убедитесь, что все ключевые критерии приёмки у истории есть, они обсуждены и понятны команде, и что команда понимает, что именно считается «Выполнено».
Что означают большие числа в оценках?
Оценка, как мы уже проговорили, показывает сложность, а не срок выполнения работы. Но при этом есть некоторые эмпирические ориентиры для команды, чтобы понять, не слишком ли это большая история. Напомню, что история не может выполняться дольше, чем длится итерация (а это обычно 2 недели), в которую команда взяла её в работу.
Если держать в голове ориентир непрерывного выполнения истории командой, то скорее всего:
- 5 – будет означать, что история займёт примерно половину календарного времени итерации,
- 8 – скорее всего будет выполнена к концу итерации, если команда сразу начнёт выполнять эту историю с началом итерации,
- 13 и более будет означать, что историю скорее всего не удастся уложить в календарный период одной итерации, и её точно нужно будет разбивать на несколько более мелких (декомпозировать). Возможно, здесь потребуется дополнительно сформулировать какие-то новые исследовательские истории (спайки, исследовательские энейблеры), чтобы команда смогла на основе экспериментов позже продвинуться с декомпозицией этой истории.
Когда речь заходит о декомпозиции истории из-за её большой оценки у продуктовой команды (Менеджеры/Управляющие продукта и Владельцы продукта) может возникать вопрос: «Как же мы доставим ценность клиенту при такой небольшой сложности? Это невозможно!».
Хотелось бы напомнить, что клиентская ценность в SAFe в первую очередь должна достигаться на уровне Фич. Истории также являются элементами ценности, которые можно независимо обсудить, разработать, протестировать и продемонстрировать, но нет жёсткого требования, чтобы эта небольшая часть ценности создавала обособленную и понятную часть ценности для конечного клиента.
На уровне историй достаточно, чтобы Владелец продукта и команда совместно понимали, в чём этот небольшой элемент ценности заключается, и, если ценность для конечного клиента не появляется в момент окончания работы над историей, идентифицировали бы эту историю как один из видов энейблеров (SAFe рассматривает как минимум 4 базовых вида энейблеров.
Относительная оценка – это примерная оценка!
Большие интервалы между числами на шкале сделаны не случайно: оценка грубая, дискретная. Поэтому простая рекомендация: важно не углубляться в долгие обсуждения деталей. Достаточно договориться об уровне принятой дискретности и двигаться к оценке следующей истории.
Какая сложность историй чаще всего встречается в «здоровом» беклоге итерации?
Сразу озвучим ответ. У хорошего Владельца Продукта и со зрелой командой подавляющее большинство историй будут скорее всего иметь размер 1, 2 или 3 сп. Объясню почему:
- чем «меньше» история, тем меньше и ошибка в оценке этой истории;
- чем меньше ошибка, тем выше вероятность выполнить набор историй;
- чем выше вероятность выполнить истории, тем выше вероятность выполнить цель итерации.
Истории с большой оценкой часто создают иллюзию прогресса («мы заняты»), но часто на практике «ломают» доставку («ничего не Выполнено»).
Подведём итог
Давайте разберёмся, как предложенные выше техники использования относительных оценок помогают решать задачу управляемости на уровне нескольких команд и всей организации. Какие важные техники мы обсудили выше:
- правило, как определить сложность в 1 пункт/балл выполнения истории (сторипоинт);
- правило, как оценивать истории относительно той, которую мы приняли за «1»;
- логику связки оценок ёмкости команды и средней пропускной способности, которые нам нужны для выстраивания прогнозов.
Предложенные техники устанавливают единые правила калибровки, благодаря чему размерность сторипоинта в разных командах отличается, но не радикально. Это позволяет на уровне продукта, поезда и т.д.:
- суммировать относительные оценки историй разных команд для определения сложности фич,
- строить дорожные карты на основании расчётной пропускной способности,
- при подготовке и проведении мероприятий по планированию интервалов (PI-Планирований) оценивать, «помещаются ли» фичи в интервал, или их нужно декомпозировать / переприоритизировать,
- принимать инвестиционные решения без возврата к человеко-часам, поскольку для инвестиционных целей мы можем вывести среднюю стоимость сторипоинта для поезда, продукта или потока,
- осуществлять бухгалтерский учёт, необходимый для учёта расходов, амортизации и капитализации, поскольку на основании сторипоинтов и фактических расходов можно относительно легко вычислить суммы, подлежащие распределению по соответствующим счетам.
Дополнительно почитать:
Планирование Итерации (Iteration Planning) в SAFe
Цели Итерации: зачем нужны и как использовать в SAFe?
Ретроспектива Итерации: цель, участники, программа, рекомендации по фасилитации, результаты.
© «Ионов и Партнеры» (ИП Ионов Алексей Константинович), 2018-2025. Все права защищены. Цитирование материалов и размещение ссылок на материалы для формирования сторонних баз знаний, рубрикаторов или агрегаторов допускается только с письменного согласия «Ионов и Партнеры».
SAFe® and Scaled Agile Framework® are registered trademarks of Scaled Agile, Inc.